

Orientation Over Reasoning
ORIENTATION OVER REASONING
By Hussain Sultan, Paddy Mullen, George Hoersting | April 22, 2026
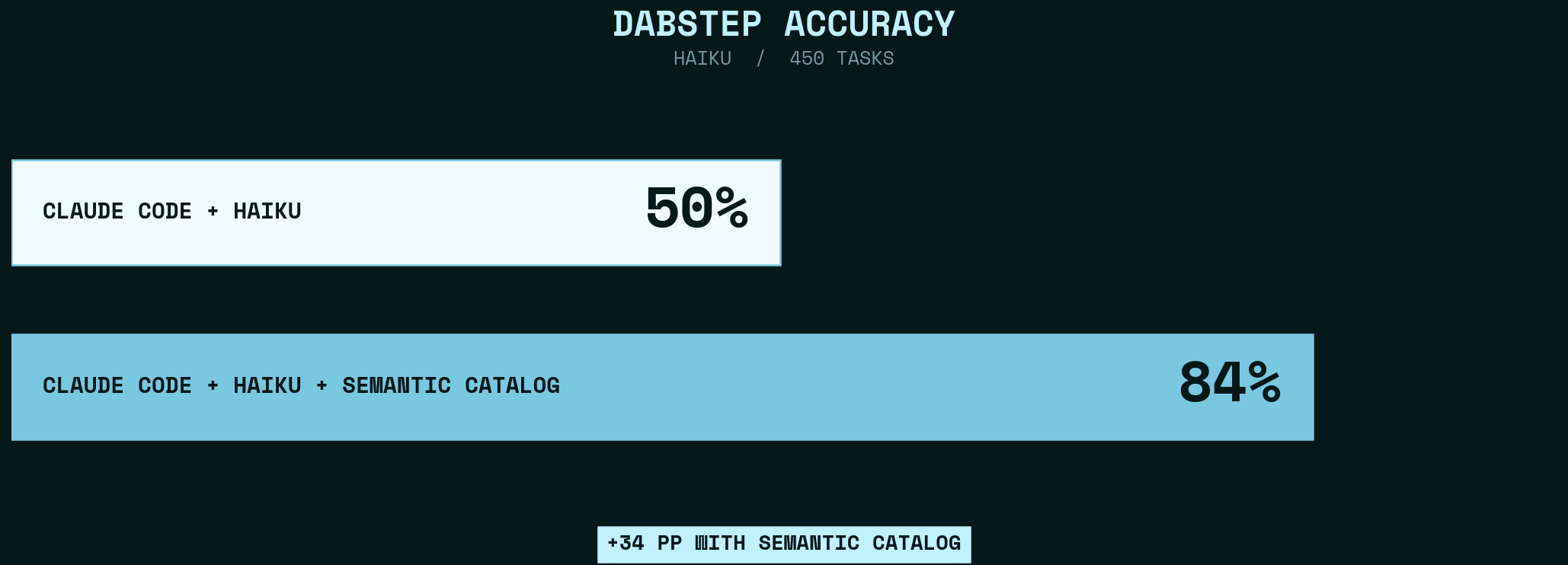
How a semantic catalog and a short CLAUDE.md took Haiku from 50% to 84% on DABStep

This is our customary benchmark figure — see Fair Benchmarking Considered Difficult (Raasveldt & Holanda). Our results are fully reproducible: a nix flake provides the environment, all data is downloaded from Hugging Face, and the full chat conversations and pytest harness are available for users to run.
We used DABStep — a benchmark of 450 data-analysis questions over payment transaction data — to compare two agent harnesses1: a baseline bare-Haiku harness, and a harness with access to a xorq semantic catalog. The 450 data-analysis questions aren’t simple lookups: they require joining multiple data sources, applying domain-specific fee formulas, disambiguating concepts like “fraud rate” (EUR-based ratio, not count), and formatting answers precisely.
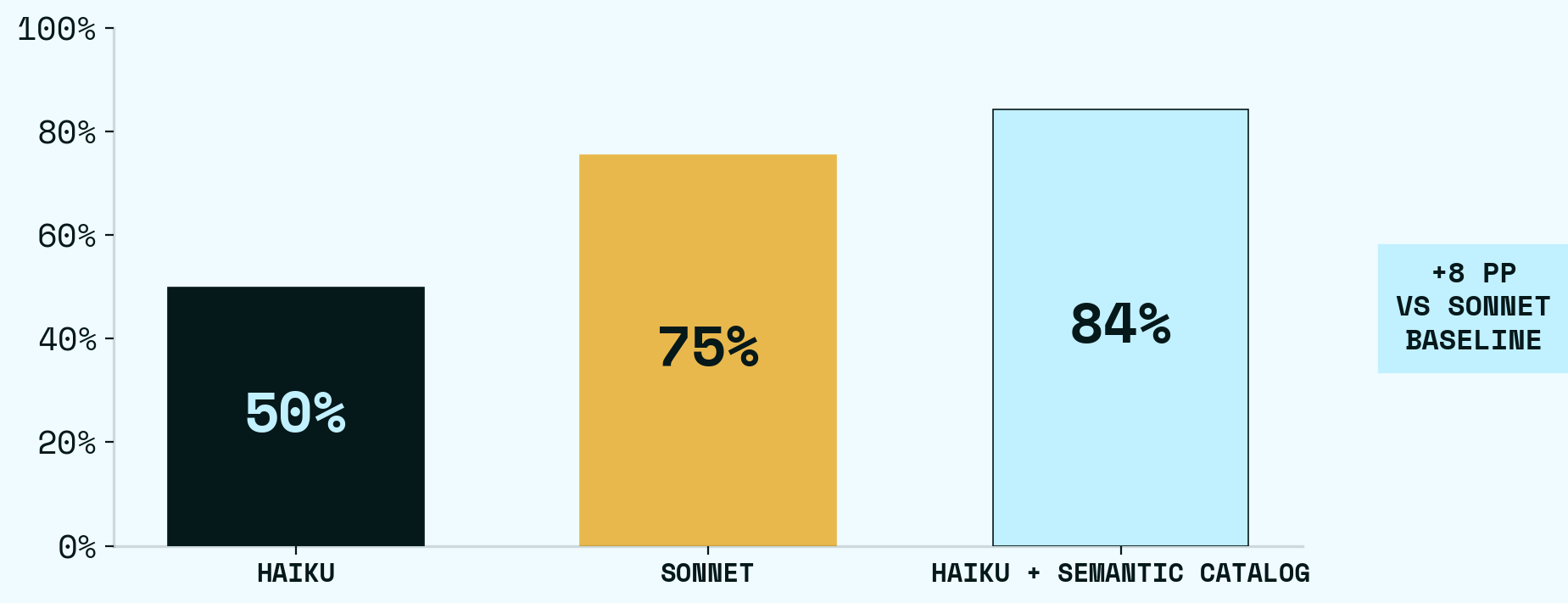
The baseline harness gives Claude Haiku raw CSV/JSON files and a manual.md that documents the domain’s schemas and business rules. It scored 50%.
The catalog harness adds a tool that uses xorq as a context layer — a semantic catalog of 33 named expressions, built on two boring-semantic-layer models, that expose the domain’s data as queryable tables — and a short CLAUDE.md pointing the agent at it. It scored 84%.
We found that guiding an LLM where to look for context mattered more than base model intelligence. Each catalog entry made the agent measurably better at answering questions it was already smart enough to understand — while using fewer tokens, fewer turns, and less wall-clock time per question.
| Repository | xorq-labs/bench-dabstep |
| Result logs | logs/ |
| Try it yourself | nix run github:xorq-labs/bench-dabstep |
How we tested this
The experiment design is simple: hold everything constant except how the agent finds data.
Both conditions — baseline and catalog — share the same pytest harness, the same Claude Code version (v2.1.96), the same scoring logic, and the same rules section in CLAUDE.md. The model is Haiku throughout. Each task gets 25 turns and 300 seconds. At test time, the harness creates an isolated git worktree per question, drops in the experiment’s CLAUDE.md, and runs claude -p with full autonomy. No human in the loop. 450 questions, scored against a publicly available Hugging Face submission as ground truth.
The only thing that changes between conditions is context — how the agent discovers and accesses data. Everything else is symmetric: any non-catalog improvements we made (rule clarifications, output format guidance) were applied to both experiments equally.
Here’s what that one difference looks like:
| Baseline | Catalog | |
|---|---|---|
| Harness | Claude Code | Claude Code + xorq catalog |
| Data access | Read 7 raw CSV/JSON files from data/ |
load("alias").execute() via xorq catalog |
| Schema discovery | Read manual.md and payments-readme.md |
xorq catalog list-aliases / schema <alias> |
| Semantic model | None | Queryable dimensions and measures |
| CLAUDE.md | 40 lines, 2,495 chars, 5 sections | 31 lines, 1,988 chars, 3 sections |
| Column naming | is_credit, merchant_category_code |
applies_to_credit, mcc (matches the model schema) |
Notice the prompt: the catalog agent harness’s CLAUDE.md is 20% smaller. It has fewer instructions because it needs fewer instructions — the catalog carries the context that the baseline agent harness has to reconstruct from scratch.
The full experiment is reproducible. Clone the repo, enter the nix shell, run pytest with the split and model flags. Results land in a long-format parquet table — two rows per task, one per condition — scored by the DABStep scorer.
What the scores actually measure
The DABStep question set is publicly available, so absolute scores on this benchmark are no longer a legitimate leaderboard claim — the test has been compromised. But the benchmark is still meaningful for comparing approaches head-to-head, which is what we’re doing here. Our agent computes answers live — nothing is hardcoded — but the score isn’t the point. The point is what thousands of agent sessions taught us about how agents use data: accuracy depends on the combination of a discoverable semantic catalog and prompt routing that points the agent at the right entries. Neither alone is sufficient — catalog without routing reaches 80%, routing without catalog is the baseline.
To be clear about what we did: we looked at the benchmark questions, identified the common patterns that require tricky data engineering (fee matching, fraud rate computation, scheme steering), and built xorq expressions that pre-compute those patterns into queryable tables. In spirit, expressions are reusable tools available to the agent. This is similar in spirit to the helpers.py that NVIDIA’s top-scoring solution constructs automatically — except our catalog is built by a human with domain knowledge, versioned, and reusable beyond the benchmark. We aren’t competing for the leaderboard. We’re showing what happens when an agent has access to a well-built semantic catalog.
What the baseline agent harness faces
To make this concrete, here’s what a typical question looks like. The benchmark asks: “Which card scheme should Rafa_AI steer traffic to in order to minimize fees in March?”
The baseline agent harness has raw CSV and JSON files. To answer this, it needs to:
- Load 138,000 transactions from
payments.csvand merchant attributes frommerchant_data.json - For each of 4 candidate card schemes, filter to the right merchant and month
- Compute monthly fraud rate and volume (needed for fee rule matching)
- Cross-match every transaction against ~1,000 fee rules in
fees.json, checking 10 fields simultaneously — card scheme, account type, MCC, is_credit, ACI, intracountry, and four range-based fields for fraud and volume bands - Apply the fee formula (
fixed_amount + rate * transaction_value / 10000) for each matching rule - Sum fees per candidate scheme and return the minimum
That’s 50–100 lines of careful pandas, with plenty of room for subtle errors: wrong matching logic on fee rule wildcards, confusing the actual transaction scheme with the candidate scheme, computing fraud rate by count instead of EUR volume. The baseline agent harness gets the raw files, a domain manual, and a CLAUDE.md that says “read the manual, load the CSVs, analyze with Python.”
What the catalog agent harness does
The catalog has 33 entries. 10 derive from two boring-semantic-layer models (semantic-payments and transaction-fee-model): the models define joins, aggregations, and domain logic once, and 8 downstream expressions bake that logic into flat tables for specific use cases — monthly fees, daily fees, fee breakdowns, fraud targeting. The other 23 — 4 raw source expressions and 19 transform expressions — derive independently, doing their own joins and aggregations.
In practice, the agent overwhelmingly uses the catalog as a directory of named dataframes — pick an alias, get back the table you need. The semantic model’s value isn’t in its query API — it’s in the downstream expressions it produces. Agents don’t need to understand dimensions and measures — they just need to pick the right alias.
When the agent does use the semantic model directly, the code is compact:
“What is the highest avg fraud rate for 2023? (by card_scheme)”
model = load("semantic-payments").ls.builder
df = model.query(
dimensions=("card_scheme", "year"),
measures=("fraud_volume", "volume")
).execute()
df_2023 = df[df['year'] == 2023]
df_2023['fraud_rate'] = df_2023['fraud_volume'] / df_2023['volume']
highest_fraud_rate = df_2023['fraud_rate'].max()The CLAUDE.md diff
Both conditions share the same domain rules. The catalog agent’s CLAUDE.md replaces file listings and manual references with catalog discovery:
-You are solving a data analysis benchmark task. You have access to data files
-in the `data/` directory of this repository.
-
-## Execution Rules
-- Always execute code yourself. Never ask the user to run code.
-- Never ask for confirmation. Just compute and answer.
-
-## Available Data Files
-- `data/payments.csv`
-- `data/fees.json`
-- `data/merchant_data.json`
-- ...
+## How to Answer
+```python
+from load import load
+df = load("alias-name").execute()
+```
+
+Discover entries: `xorq catalog -p git-catalogs/dabstep list-aliases`
+
+Semantic model entries support `.ls.builder`:
+```python
+model = load("semantic-payments").ls.builder
+model.query(dimensions=("merchant", "month"), measures=("volume",)).execute()
+```The rules section is identical between conditions — same format examples, same fee formula, same fraud rate definition. The only catalog-specific additions are two lines: that raw-aci-fee-candidates is fraud-only, and that credit filtering uses applies_to_credit instead of is_credit (because the catalog’s normalized fee table pre-computes this).
Better, Cheaper, Faster
Adding the semantic catalog improved Haiku significantly — on the same model, same data, same rules. The only thing that changes is how the agent finds what it needs. Haiku alone scores 50%. Haiku with the catalog scores 84% — a +34 pp jump. But accuracy is only one axis. Haiku with the catalog is also cheaper (tokens) and faster (turns): Average tokens drop 60% (566k → 228k), average turns drop 56% (14.3 → 6.2). Every panel moves in the right direction at once.
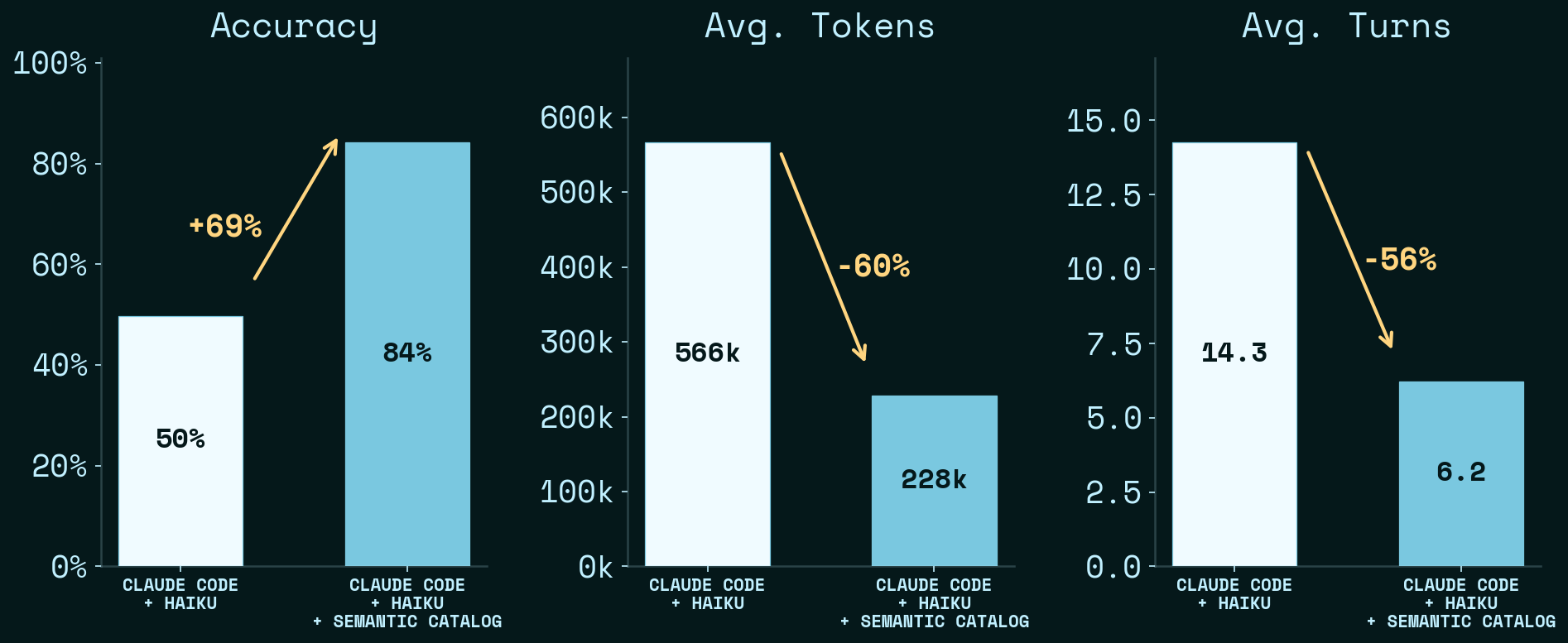
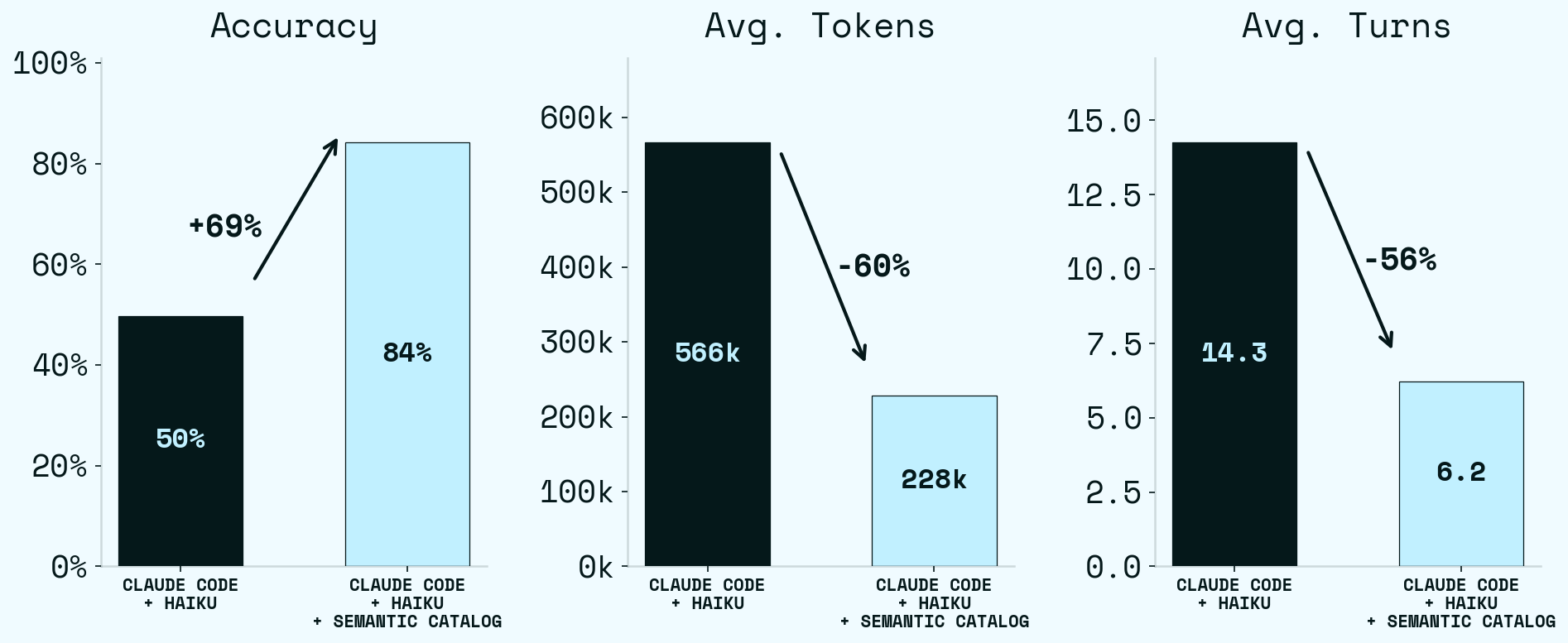
The typical catalog session is just load and filter:
df = load("scheme-steering").execute()
result = df[(df['merchant'] == 'Martinis_Fine_Steakhouse') & (df['month'] == 10)]
min_row = result.loc[result['total_fee'].idxmin()]Three turns. The scheme-steering table has already cross-joined every transaction with every candidate scheme, matched against fee rules, applied the fee formula, and summed per scheme. No .builder, no .query() — just load and filter.
With 33 entries the catalog becomes a routing table. The agent’s job reduces to picking the right alias and filtering the result — the reasoning that the baseline agent has to do is already baked into the expressions. More entries means less reasoning required. Fewer turns means less latency, lower cost, and fewer wrong paths.
A stronger model is not enough
We ran the same experiment with Sonnet. Sonnet baseline (75%) is stronger than Haiku baseline (50%) — the bigger model helps. But Haiku + Semantic Catalog (84%) still outperforms Sonnet baseline outright, while costing a fraction as much per task.
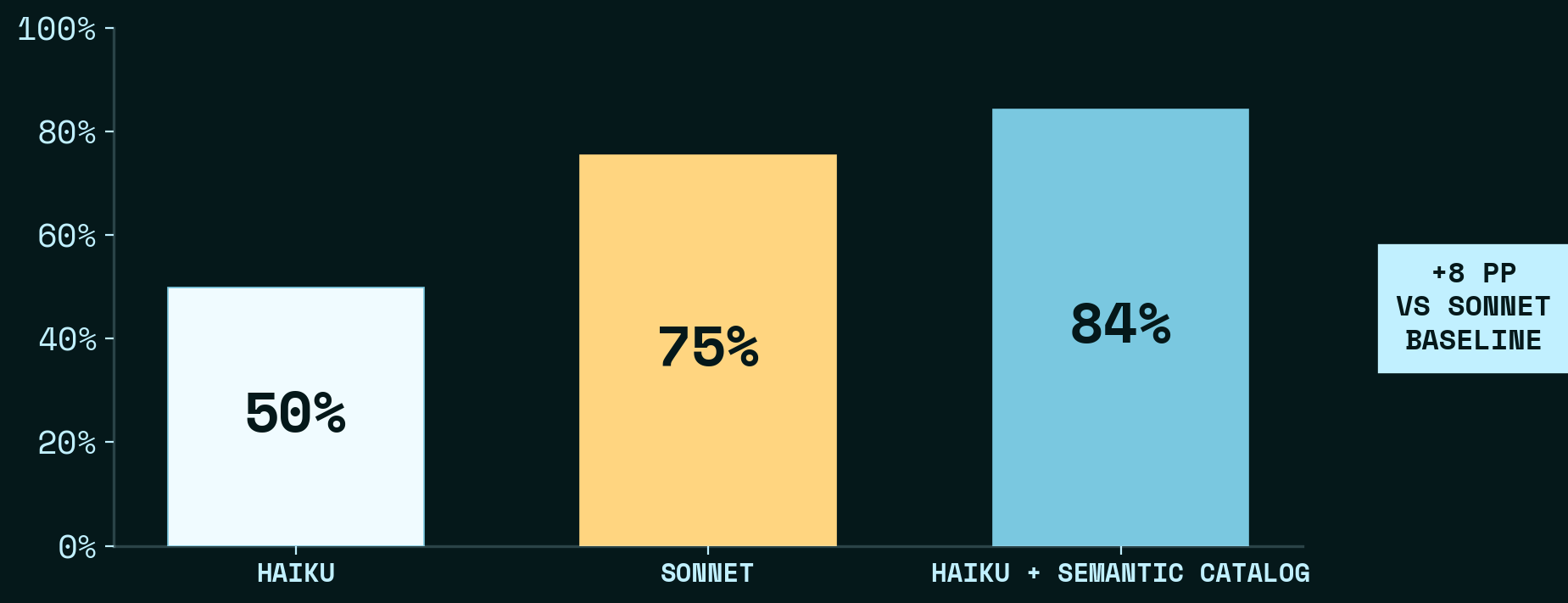
The catalog helps Haiku far more than Sonnet: +34 pp lift vs +16 pp for Sonnet. Sonnet’s baseline is already strong, so there’s less room for the catalog to rescue; Haiku’s baseline has much more headroom, and the catalog fills it.
Better orientation lets you use a cheaper model and still come out ahead.
What this means
The conventional playbook for improving LLM accuracy is to upgrade the model, add more tokens, or build elaborate prompting strategies. Our results suggest a different lever: invest in the context layer.
Both conditions have access to the same underlying data. The difference is how that data is presented to the agent — raw files vs. named, typed, pre-computed expressions with discoverable schemas and semantic meaning encoded. The catalog doesn’t add data. It adds context: structured orientation that tells the agent what exists, what it means, and how to access it.
Building that context layer is real work — someone has to understand the domain, identify which computations the agent will need, and encode them as named expressions. Our process was iterative: run the benchmark through our harness, look at where the agent was failing, and build expressions that cover those gaps. Each iteration tightened the feedback loop between what the agent needed and what the catalog provided. It’s the kind of work a data engineer already does when building a semantic model; the difference is that the consumer is an LLM agent instead of a dashboard.
But that investment compounds. Together, the catalog and a short CLAUDE.md took Claude Haiku from 50% to 84% on DABStep2.
The implication for anyone building agentic workflows over data: the bottleneck probably isn’t the model. It’s the context the agent starts with. A bigger model can reason harder, but it can’t conjure correct fee-matching logic from ambiguous documentation. A catalog gives the agent the right orientation — and every expression you add removes a class of errors from its path.
Copy our address and paste it into whichever email client you use.
Footnotes
The official DABStep benchmark uses smolagents as its harness. We deviate from it because our goal isn’t leaderboard placement but measuring the impact of structured context on a coding-agent harness like Claude Code.↩︎
In prior runs with a question routing table in CLAUDE.md — a markdown table mapping question patterns directly to catalog aliases — Haiku reached 92.4%. The results reported here (84%) do not include a routing table; the agent discovers aliases via
list-aliasesand selects on its own. The routing table eliminates ~8 points of stochasticity by removing alias selection from the agent’s decision space entirely. We omit it from the main results because it encodes benchmark-specific knowledge that wouldn’t generalize to new question types.↩︎