[ Open Compute Format for Ai ]
Define once, run anywhere—Xorq lets teams catalog, share, and serve ML in pure Python with declarative, portable, and governed expressions.
Simplify ML data processing with open source Xorq
from xorq.ml import deferred_fit_predict_sklearn
deferred_model, model_udaf, predict = deferred_fit_predict_sklearn(
expr=encoded_train,
target="deposit",
features=["encoded", "balance"],
cls=MyEstimator,
)
predictions = encoded_test.mutate(predicted=predict.on_expr(encoded_test))from xorq.quickstart import transform_predict
pipeline = fetcher_expr.select("title").mutate(sentiment=transform_predict.on_expr)
❯ xorq build scripts/hn_inference.py -e pipelinepg = xo.postgres.connect_env()
ddb = xo.duckdb.connect()
expr = pg.table("batting").filter(_.yearID == 2015).into_backend(ddb).group_by("teamID").agg(_.G.mean())from xorq.caching import ParquetStorage
expr = (
xo.examples.iris.fetch()
.filter(_.species == "Setosa")
.cache(storage=ParquetStorage(source=xo.connect()))
)from xorq.common.utils.lineage_utils import build_column_trees, print_tree
trees = build_column_trees(expr)
print_tree(trees["total_discount"])The Missing Layer in AI Infrastructure
Modern storage formats like Iceberg solve data reproducibility.
But compute—the transformations, features, models—remains brittle and siloed.
Xorq is the compute catalog: a unified layer to declare, reuse, and observe every expression of compute—across engines, teams, and environments.
Legacy
With Xorq



Next-level Reusability
You've never experienced reuse like this.
Reusable Xorq "expressions" integrate seamlessly with Python. Easy to share and discover with compile-time validation and clear lineage.
Your AI Engineering Catalog
Innovate fast and confidently. Xorq automatically catalogs your AI compute artifacts as you go to facilitate reuse, troubleshooting, and quality.

Fast Iteration. Lower Compute Costs.
By the time you have it working locally, it's already optimized for production, with caching, millisecond data exchange, and other high-performance features.

Put an End to ML Silos
One platform to support your entire AI engineering organization. Securely share and discover reusable artifacts across individuals, teams, and partners.
Accelerate AI Innovation
A compute catalog is a powerful asset. Share and discover reusable expressions, combine them into new composite expressions, and observe and troubleshoot their behavior.
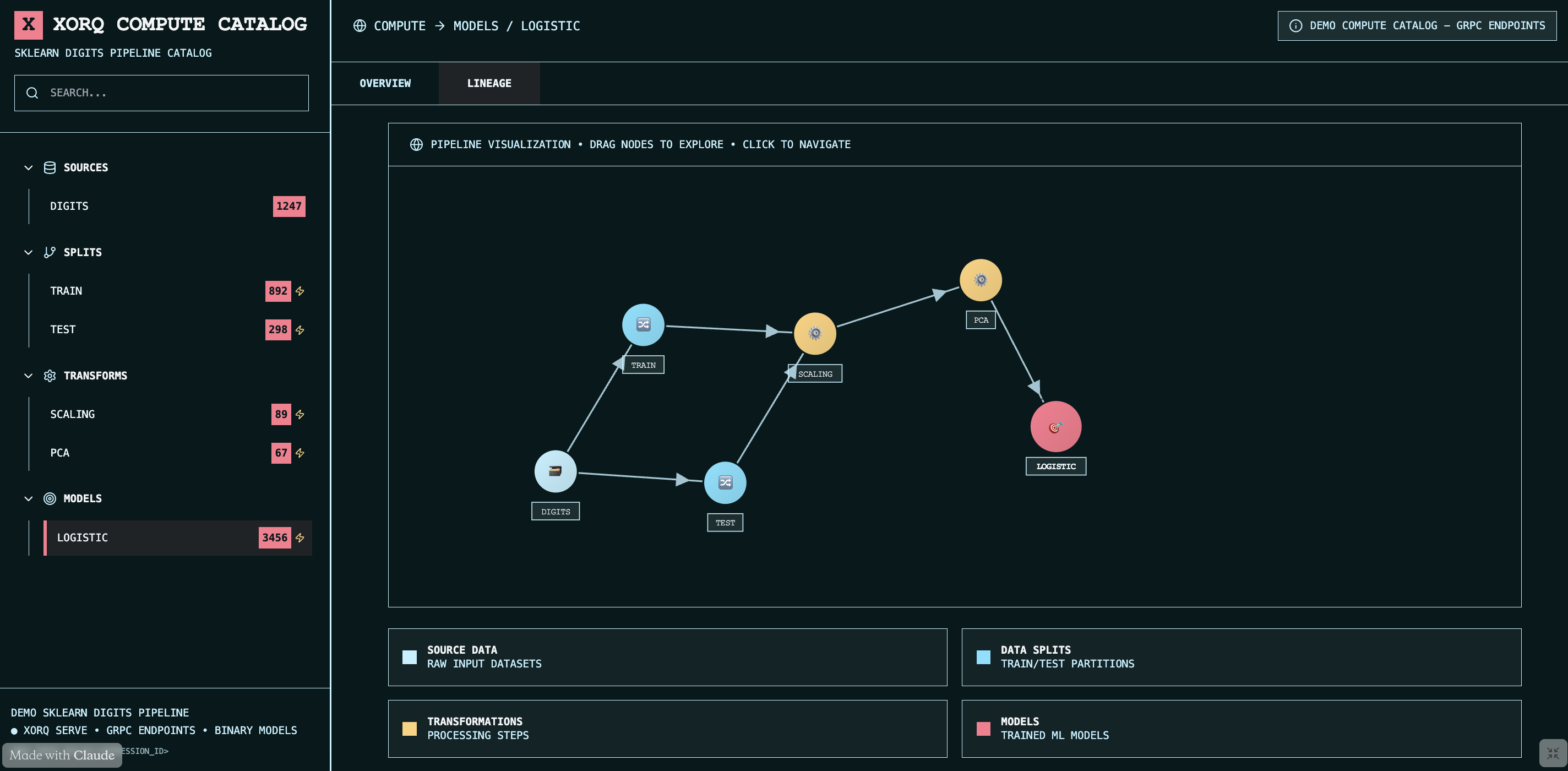
Just build, run, and serve.

Declare and compile multi-engine Python
Xorq catalogs every expression: versioned, composable, lineage-tracked artifacts represented as YAML format.

Build Once, Run Anywhere.
Run Xorq expressions as portable UDXFs with cross-engine optimizations, caching & observability.

High-performance Catalog Servers
Create portable Catalog Servers, with millisecond data transfer via Apache Arrow Flight.
Plug xorq into your stack
From experimentation to production, xorq fits into the workflows your team already uses—without forcing new tools or rewrites.
Get started with Xorq
Start yourself or request your free build.
Install Xorq
Spin up your first Xorq engine in minutes—locally or in the cloud.
Request a demo
Not sure where to start? We’ll build your first Xorq UDXF—free. Tailored just to your stack, your use case, and your goals.
Start with a template
Start with a pre-built pipeline tailored to real-world ML tasks—modify it, run it, and make it yours in minutes.
Tutorials, Insights & Updates
Ideas and insights from a team building the most portable pipeline runtime.

Xorq: The Open Compute Format for AI Data Engineering

From FeatureStore to FeatureHouse
.jpg)
Pipelines as UDFs
FAQs
Find answers to common questions about Xorq below.
Xorq is an open-source compute format for AI; a unified layer to declare, catalog, reuse, and observe every expression of compute—across engines, teams, and environments.
Xorq was created by a team of data scientists on a mission to help others accelerate AI innovation by simplifying and standardizing the declaration, reuse, portability, and governance of ML data processing.
Xorq is very easy to adopt. The open source library enhances Python with a declarative pandas-style syntax for defining AI data processing. It abstracts away implementation and data engineering details that normally complicate AI data processing and slow down production deployment.
You can explore our documentation for detailed guides and tutorials. Additionally, our blog features insights and updates on xorq's capabilities. Join our community for discussions and shared learning experiences.
Still have questions?
We're here to help you!
Simpler ML,
Faster AI innovation.
Try Xorq today, or request a walkthrough.
